By Jim Clifford
Nineteenth century place names are a major challenge for the Trading Consequences project. The Edinburgh Geoparser uses the Geonames Gazetteer to supply crucial geographic information, including the place names themselves, their longitudes and latitudes, and population data that helps the algorithms determine which “Toronto” is most likely mentioned in the text (there are a lot of Torontos). Based on the first results from our tests, the Geoparser using Geonames works remarkably well. However, it often fails for historic place names that are not in the Geonames Gazetteer. Where is “Lower Canada” or the “Republic of New Granada“? What about all of the colonies created during the Scramble for Africa, but renamed after decolonization? Some of these terms are in Geonames, while others are not: Ceylon and Oil Rivers Protectorate. Geonames also lacks many of the regional terms often used in historical documents, such as “West Africa” or “Western Canada”.
To help reduce the number of missed place names or errors in our text mined results, we asked David Zylberberg, who did great work annotating our test samples, to help us solve many of the problems he identified. A draft of his new Gazetteer of missing 19th century place names is displayed above. Some of these are place names David found in the 150 page test sample that the prototype system missed. This includes some common OCR errors and a few longer forms of place names that are found in Geonames, which don’t totally fit within the 19th century place name gazetteer, but will still be helpful for our project. He also expanded beyond the place names he found in the annotation by identifying trends. Because our project focuses on commodities in the 19th century British world, he worked to identify abandoned mining towns in Canada and Australia. He also did a lot of work in identifying key place names in Africa, as he noticed that the system seemed to work in South Asia a lot better than it did in Africa. Finally, he worked on Eastern Europe, where many German place names changed in the aftermath of the Second World War. Unfortunately, some of these location were alternate names in Geonames and by changing the geoparser settings, we solved this problem, making David’s work on Eastern Europe and a few other locations redundant. Nonetheless, we now have the beginnings of a database of place names and region names missing from the standard gazetteers and we plan to publish this database in the near future and invite others to use and add to it. This work is at an early stage, so we’d be very interested to hear from others about how they’ve dealt with similar issues related to text-mining historical documents.
 From the Trading Consequences Blog: Today we are delighted to officially announce the launch of Trading Consequences! Over the course of the last two years the project team have been hard at work to use text mining, traditional and innovative historical research methods, and visualization techniques, to turn digitized nineteenth century papers and trading records (and their OCR’d text) into a unique database of commodities and engaging visualization and search interfaces to explore that data. Today we launch the database, searches and visualization tools alongside the Trading Consequences White Paper, which charts our work on the project including technical approaches, some of the challenges we faced, and what and how we have achieved during the project. The White Paper also discusses, in detail, how we built the tools we are launching today and is therefore an essential point of reference for those wanting to better understand how data is presented in our interfaces, how these interfaces came to be, and how you might best use and interpret the data shared in these resources in your own historical research. READ MORE
From the Trading Consequences Blog: Today we are delighted to officially announce the launch of Trading Consequences! Over the course of the last two years the project team have been hard at work to use text mining, traditional and innovative historical research methods, and visualization techniques, to turn digitized nineteenth century papers and trading records (and their OCR’d text) into a unique database of commodities and engaging visualization and search interfaces to explore that data. Today we launch the database, searches and visualization tools alongside the Trading Consequences White Paper, which charts our work on the project including technical approaches, some of the challenges we faced, and what and how we have achieved during the project. The White Paper also discusses, in detail, how we built the tools we are launching today and is therefore an essential point of reference for those wanting to better understand how data is presented in our interfaces, how these interfaces came to be, and how you might best use and interpret the data shared in these resources in your own historical research. READ MORE
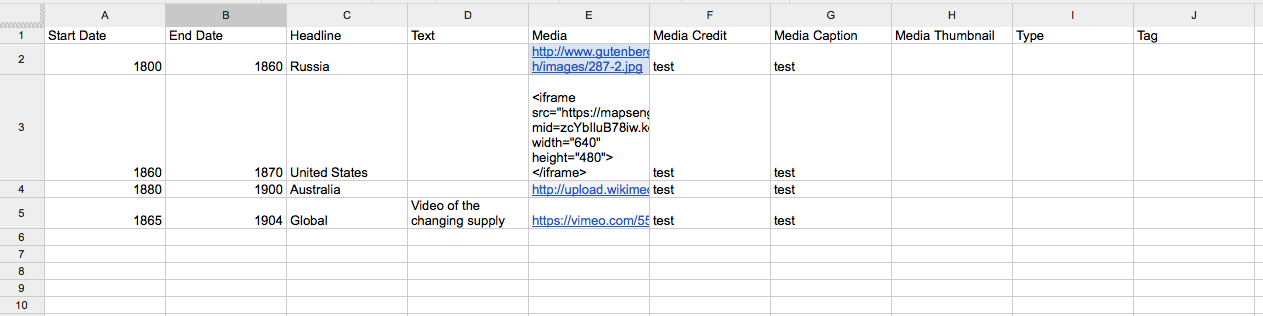
 I’ve been a part of a lot of discussions lately about the need for an effective way to share HGIS data. As the number of researchers using GIS for history/historical geography increases, the need to find ways of sharing resources and avoiding duplicated efforts also increases. One way forward is for more of us to post our data on individual websites (see the
I’ve been a part of a lot of discussions lately about the need for an effective way to share HGIS data. As the number of researchers using GIS for history/historical geography increases, the need to find ways of sharing resources and avoiding duplicated efforts also increases. One way forward is for more of us to post our data on individual websites (see the 