I’ve been informed that my original download missed a lot of the files. I’m going to recreated the two graphs below over the next few days with the missing data and rework this post.
I’m working with Bea Alex on a blog post for the Kew Garden Directors’ Correspondence project. They shared their meta data collection with Trading Consequences and Bea reformatted it into a directory of 7438 xlm files (one for every letter digitized to date by the project). The metadata includes all the information found on the individual letter webpages (sample). Bea and the rest of the team in Edinburgh focused on extracting commodity-place relationships from the description field. We’re currently working with the data for coffee, cinchona, rubber, and palm to create an animated GIS time-map for the blog post we are writing. However, because this is one of the smallest collections we are processing in the Trading Consequences project, I decided to try and play around with the data a little more.
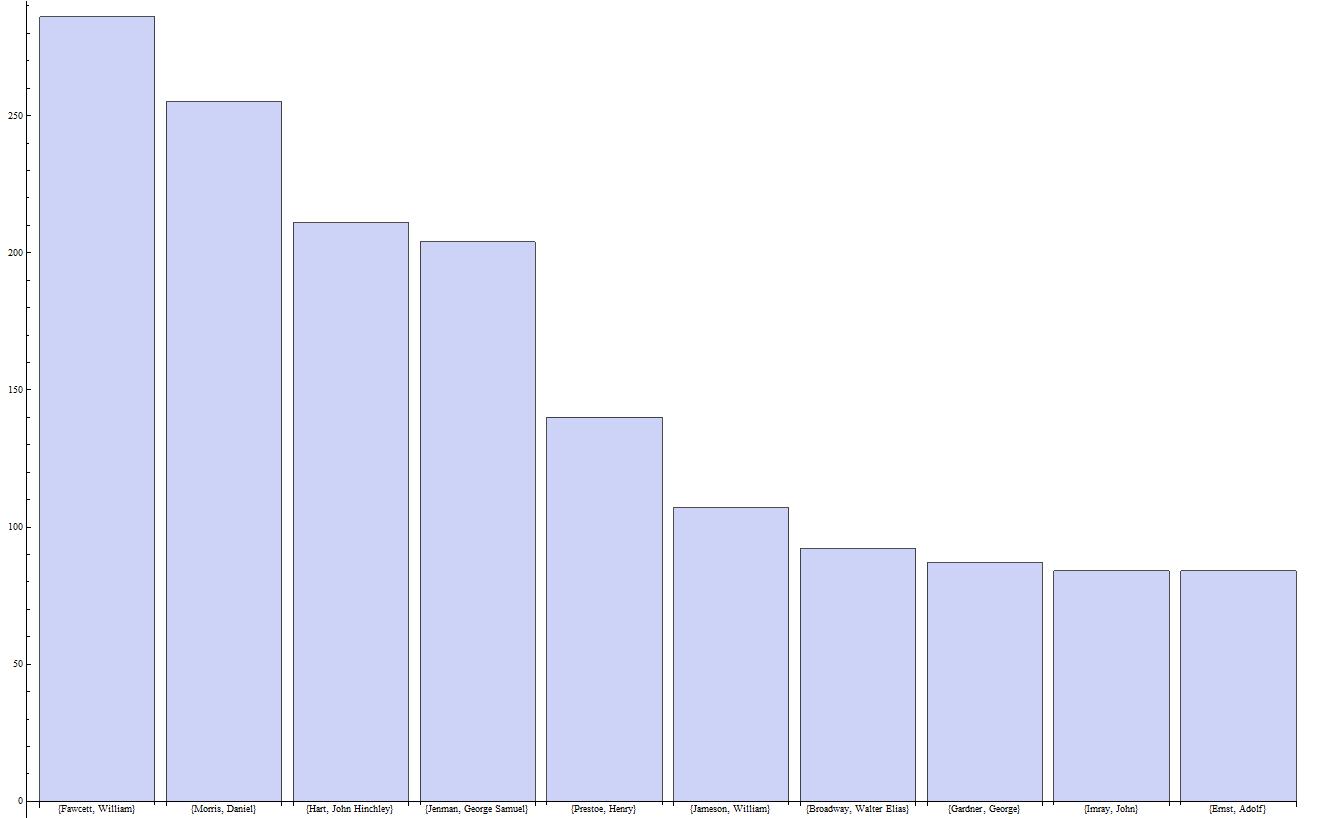
XML files are pretty ubiquitous once you start working with large data sets. They are generally easier to read and more portable than standard relational databases and presumably have numerous other advantages. The syntax is familiar if you know HTML, but I’ve still found it challenging to learn how to pull information out of these files. As with most things, coding in Mathematica, instead of Python, makes it easier. It turned out to be relatively straight forward to import all 7438 xml files, have Mathmatica recognize the pattern of the “Creator” field and pull out a list of all of the letter authors. From there, it was easy to tally up the duplicates, sort them in order of frequency (borrowing a bit of code from Bill Turkel) and graph the top ten (of the 1689 total authors).

